
来源| 海克财经
产业化落地是关键。
AI领域又添波澜。
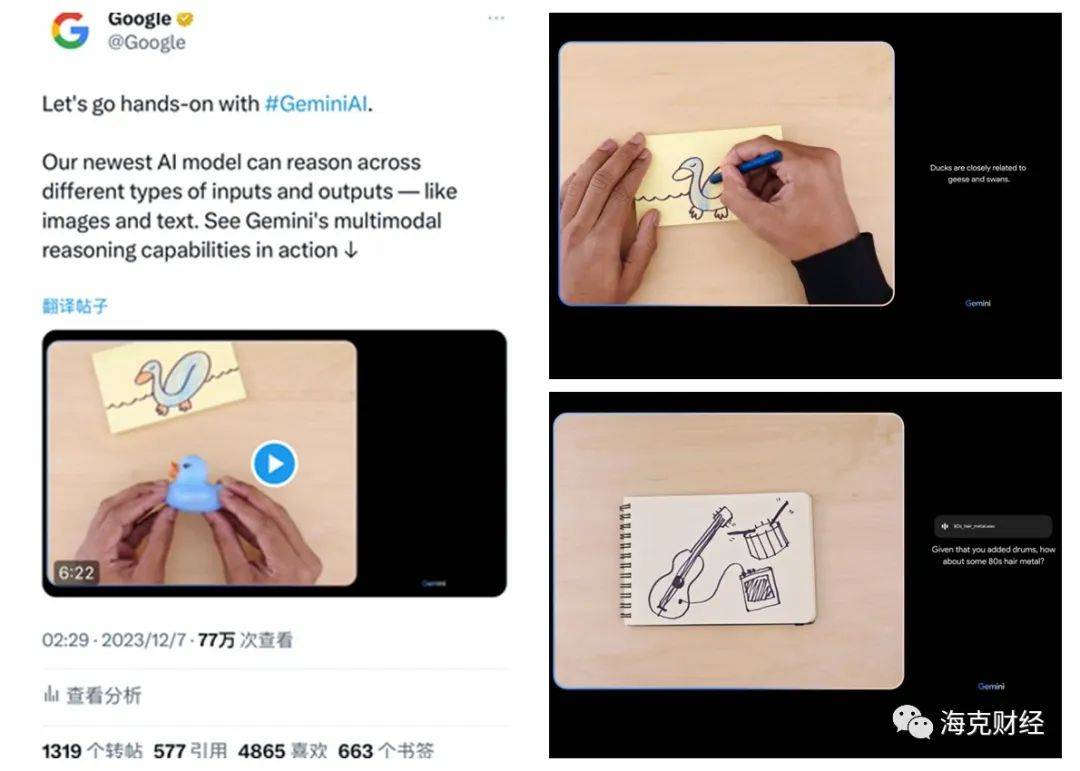
12月7日,酝酿已久的谷歌正式发布了Gemini多模态大模型。
官宣Gemini 1.0版本中包含Gemini Ultra、Gemini Pro、Gemini Nano这3个不同尺寸,Gemini Nano主要应用于设备端,Gemini Pro适用于在各种任务中扩展,功能最为强悍的Gemini Ultra仍在进行信任和安全检查,并进行微调和基于人类反馈的强化学习,预计2024年初向开发人员和企业客户推出。

在此之前,IBM宣布联合Meta与AMD、英特尔、甲骨文、康奈尔大学、耶鲁大学、加州大学伯克利分校等合作推出“AI联盟”,共同支持AI的开放创新。IBM董事长阿尔温德·克里希纳表示,IBM希望通过合作,让AI联盟能够在安全性、责任性和科学严谨的基础上推进创新型AI的议程。
颇为显眼的是,AI联盟的合作机构名单中并无谷歌以及ChatGPT背后公司OpenAI的身影。不少业内人士认为,这是在“抱团”抗衡巨头。
由ChatGPT掀起的大模型浪潮早已席卷而至。ChatGPT问世已有1年,国内外均是“百模大战”。据《北京市人工智能行业大模型创新应用白皮书》,截至2023年10月,国内10亿参数规模以上的大模型厂商及高校院所共计254家。
其中开源大模型的发展尤为令人瞩目。
国内枪声先响的是原搜狗CEO王小川创立的百川智能。2023年6月,百川智能发布可免费商用的70亿参数开源语言模型Baichuan-7B,1个月后又发布了130亿参数语言模型Baichuan-13B及对话模型Baichuan-13B-Chat。9月,百川智能宣布将调整后的Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat与其4bit量化版本开源。
另一位重磅开源玩家是阿里云。
自2023年8月起,阿里云陆续开源了70亿参数通用模型Qwen-7B、对话模型Qwen-7B-Chat、视觉语言模型Qwen-VL、140亿参数模型Qwen-14B及其对话模型Qwen-14B-Chat。12月1日,阿里云又宣布开源720亿参数模型Qwen-72B,一同开源的还有18亿参数模型Qwen-1.8B和音频模型Qwen-Audio。
至此,通义千问开源参数规模遍及18亿、70亿、140亿和720亿,加之视觉理解、音频理解两款多模态模型,可谓实现了“全尺寸、全模态”的开源。
阿里云官宣要做“AI时代最开放的云”,自然要以开源大模型押注生态建设,而通义千问正以自身迭代和演进绘制出新的落地图景。
01模型开与闭
业内早有共识,大模型的开源与闭源各有长板。
开源能带来丰富的资源和反馈,使大模型加速迭代并快速形成生态,Meta推出的LLaMA、LLaMA 2,通义千问开源“全家桶”,智普AI与清华KEG实验室推出的ChatGLM2-6B,百川部分大模型均在此列。
闭源则可以更好地保护企业的核心技术,由此提供更为独特的商业化解决方案和服务,如ChatGPT、文心一言、百川智能发布的Baichuan 53B等。
以LLaMA为例,其于2023年2月推出后便带动了一大批AI企业和机构:Stability AI推出了类似ChatGPT的Stable Chat,Stable Chat基于开源语言模型Stable Beluga,正是由LLaMA精调而来;斯坦福大学推出的Alpaca,加州大学伯克利分校主导推出的Vicuna,均是基于LLaMA的开源模型。
开放包容,发展生态,正是开源的意义。

与LLaMA 2同样开源至700亿参数级别的通义千问在影响力方面亦与之看齐。Qwen-7B开源后迅速冲上模型库HuggingFace、开发者社区Github的trending即趋势榜单。
据2023年11月1日云栖大会公布的数据,阿里云的AI大模型开源社区魔搭已聚集了2300多个模型,吸引了超过280万开发者,模型下载量突破1亿。用户可以在魔搭社区直接体验Qwen系列模型效果,也能通过阿里云灵积平台调用模型API(应用程序编程接口),或基于阿里云百炼平台定制大模型应用。
更重要的是,Qwen-72B基于3T tokens高质量数据训练,于10个权威基准测评中夺得开源模型最优成绩,各项成绩均优于LLaMA2-70B,部分测评则超越了ChatGPT-3.5和ChatGPT-4。
在英语任务上,Qwen-72B在MMLU基准测试取得开源模型最高分;而中文任务方面,Qwen-72B在C-Eval、CMMLU、GaokaoBench等基准得分超越GPT-4;在数学推理上,Qwen-72B在GSM8K、MATH测评中断层式领先其他开源模型;再看代码理解,Qwen-72B在HumanEval、MBPP等测评中的表现大幅提升,代码能力有了质的飞跃。
中文的复杂语意理解是个典型案例。将涉及“意思意思”“不够意思”“真有意思”“不好意思”等围绕“意思”不同含义的短语组成对话并提问,通义千问能够准确地剖析出每个短语在该语句或段落内的意义,譬如“不够意思”可能指对方礼物不够丰厚,“小意思”指谦虚,“不好意思”是道歉。
针对逻辑推理问题,通义千问能够展开假设来讲解答案。例如经典的“两个门卫”逻辑问题,即如何只通过一次提问,向一个说真话的门卫和一个说假话的门卫获取哪扇门才正确的答案。在回答出向任一门卫提问“如果我询问另一个门卫,对方会说哪扇门正确”这个要点后,大模型分别假设了提问真话门卫和假话门卫的情况,完整地表述了答题的逻辑。
Qwen-72B可以处理最多32k的长文本输入,在长文本理解测试集LEval上取得了超越ChatGPT-3.5-16k的效果。Qwen-72B的指令遵循、工具使用等技能均已优化,这使其能够更好地被下游应用集成。而且,Qwen-72B搭载了强大的系统指令能力,用户只需要使用一句提示词就能够定制AI助手。
据海克财经观察,输入“冷艳御姐”,大模型便会给出“有事快说,别浪费我时间”“给我放尊重一点”之类的语气;要求“二次元萌妹”,大模型则会在回答时加入各种符号表情,表述非常柔软;甚至点名影视角色,如《亮剑》中的李云龙,大模型还能将其说话方式和经典台词应用到回复中。
开源与闭源的路线之别,就像手机操作系统的iOS和Android之争,Android凭借开源打法形成了独特的生态,达到高市占率。由通义千问的表现来看,开源大模型已经迈出了重要的一步。
02商业多路径
开源大模型可以帮助用户简化模型训练和部署的过程。
用户不必从头开始训练,只需要下载预训练好的模型并进行微调,就能快速构建高质量的模型。这一面降低了各行各业进入大模型领域的门槛,一面也能反过来使具体行业促进大模型技术的进步。
国内应用于心理学场景的MindChat即是如此。
MindChat是一款心理咨询工具,可以说是AI心理咨询师,能够便捷且及时地为用户提供心理评估等服务。用户有任何烦恼或困惑都可以对MindChat倾诉,甚至可以语音输入。MindChat会共情用户,通过文字内容和语音语调分析用户的情感和心理状态,再给出相应的建议。这些建议也包括是否需要现实中的专家或心理医生介入。
用MindChat开发者颜鑫的话来说,他希望用简单易用的界面提供服务,让孤独的人找到情绪出口,保持与社会的连接。
2023年本科毕业的颜鑫是华东理工大学心动实验室成员,团队专注于社会计算和心理情感领域的AI应用开发。他发现心理服务是非常适合大模型的场景——社会对这类服务有巨大需求,但整体供给匮乏且往往价格不菲,大模型技术可以把服务变得普惠。如今MindChat已为20多万人累计提供了超过100万次的问答服务。
颜鑫和团队一直在追踪开源领域大模型的发展,此前也试用过ChatGLM、Baichuan、InternLM等大模型。Qwen-7B、Qwen-14B推出后,他们用内部数据和benchmark做了测评,认定通义千问是这一场景下开源模型里的最优解,才选择以之为基座。除了MindChat,他们团队还开发了基于通义千问的医疗健康大模型Sunsimiao(孙思邈)、教育/考试大模型 GradChat(锦鲤)。
颜鑫表示,他本人和团队都是坚定的开源支持者,所以心动实验室一部分模型对外开源,反哺开源社区,另一部分适用于真实场景的模型以闭源API的方式对外提供服务。

个人开发者陶佳同样认可大模型与具体场景的适配性。
陶佳就职于中国能源建设集团浙江省电力设计院有限公司,主要负责新型电力系统、综合能源的宏观分析、规划研究和前期优化工作。他说,从行业角度看,大模型在电力领域的应用前景从从初阶的领域知识问答系统到高阶的电力调度数学优化等,都很值得探索。因此,他尝试利用通义千问开源模型搭建文档问答相关应用。
电力领域的场景有相当的特殊性,常常需要从几十万甚至上百万字的文档中查找内容。陶佳使用通义千问做了基于私有知识库的检索问答类应用,即给定一个英文文档,告诉大模型需要查找的内容,让大模型根据文档目录回答哪个目录项下有答案。
专业领域的文档检索和解读对内容准确性和逻辑严谨性要求极高。陶佳表示,在他尝试过的开源模型中通义千问效果最好,回答准确且没有那些稀奇古怪的bug。
于陶佳而言,闭源模型如OpenAI尽管能力强,但API调用不便,更不适合像他这样的B端用户自行定制;开源模型如LLaMA可以使用,其中文能力却一般。因此,在Qwen-14B已经能做到70%以上精准度的情况下,陶佳对Qwen-72B充满了期待。
这种期待正在变成现实。12月8日,HuggingFace公布了最新的开源大模型排行榜。榜单收录了全球上百个开源大模型,测试维度涵盖阅读理解、逻辑推理、数学计算等,通义千问超越LLaMA2等国内外开源大模型登上榜首。
无论是从个人、组织还是从行业角度而言,开源都有利于形成更开放的生态。这既能令更多研究者或开发者来丰富应用和服务,也能推动大模型持续优化,不断向前。
03生态新范式
大模型的浪潮之下亦有难题。
调研机构IDC发布的《2023-2024中国人工智能计算力发展评估报告》提及,中国企业认可AIGC(生成式人工智能)在加速决策、提高效率、优化用户和员工体验等维度带来的价值,67%的中国企业已经开始探索生成式人工智能在企业内的应用机会或已经进行相关投入;与此同时,企业也需要直面计算、存储等资源短缺、行业大模型可用性待提升以及投入成本高等问题带来的压力。

颜鑫就坦诚,他们没有资源从头训练基座模型,因此在满足场景需求的情况下希望选择主流、稳定的模型架构以匹配上下游的环境,更在意开源模型背后的厂商能否持续投入基座模型和生态建设。
未来速度联合创始人兼CEO秦续业对此也有类似看法。秦续业表示,开源大模型安全、可控、可定制,还更具性价比,推理成本可能只有闭源收费大模型的五十分之一。未来速度推出的Xinference平台即基于通义千问开源模型,内置分布式推理框架,帮助企业用户在计算集群上轻松部署并管理模型。
经过简单微调,开源大模型便能满足很多B端场景需求。秦续业的公司接触的用户大部分使用的是较小尺寸模型,如Qwen-7B,使用场景如外接知识库做问答应用,通过大模型召回数据,放到上下文中进行总结并给出答案。
也就是说,通义千问提供的“全尺寸”开源模型能够让大模型触及更多用户。尽管大模型本身是开源的,企业仍可以在这个基础上提供多种形式的服务,包括定制开发、技术支持等。这不仅为自身,也为上下游企业带来了更多商业化可能性,是从生态到商业,再由商业回馈生态的正向循环。
在2023年11月的云栖大会上,阿里董事会主席蔡崇信表示,不开放就没有生态,没有生态就没有未来,而只有站在更先进、更稳定的技术能力之上,才有更大的开放底气。
一直以来,阿里都有技术开放的传统,在操作系统、云原生、数据库、大数据等领域均有自主开源项目。至此,通义千问开源的逻辑就更加清晰——既是传承,也是在通过开源方式提供更多技术产品,以此带动阿里云更长远的发展。
要知道,云和AI都离不开算力,大模型则对算力有更高要求。已经具备全栈化AI能力的阿里云在更充分地利用自己数据、算力、存储等资源长项,以开源大模型吸引更多用户进入阿里云体系。就像微软也在扩大开源模型的MaaS(模型即服务),依靠连接产业链各端来形成规模化和平台化的生态。
据海克财经了解,在官宣Qwen-72B开源的同时,阿里云还举办了首届“通义千问AI挑战赛”,参赛者可免费畅玩包括Qwen-72B在内的通义千问开源“全家桶”。
赛事分为算法和Agent两块:算法聚焦通义千问大模型的微调训练,希望通过高质量数据,探索开源模型的代码能力上限;Agent则鼓励开发者基于通义千问大模型和魔搭社区的Agent-Builder框架,开发新一代AI应用,促进大模型在各行各业的落地应用。主办方提供了价值50万元的免费云上算力和丰厚奖金。
比赛同样彰显了阿里云立足开源的决心。这意味着通义千问乃至阿里云正在以多元化、全方位的技术服务推进AI的生态繁荣,在拓宽自身边界的同时也在推进整个行业的发展。