
来源:零态LT
为什么开源大模型反而是最贵的?近日,随着Llama 3宣布开源,一则美国AI创业者Arsenii Shatokhin的采访视频在网上流传(https://weixin.qq.com/sph/AZM8h34Jm),这位AI智能体公司VRSEN的创始人表示,企业自己运行开源大模型效率低于闭源API,“我们只有一两个客户有足够资源,来精调或运行700亿参数的Llama开源模型”。


Arsenii Shatokhin已经在人工智能行业中从业六年,是美国知名的AI创业者之一。当前创业公司VRSEN专注于AI智能体,即基于大模型为企业客户打造AI Agent,从而提高销售转化率等指标。目前,Arsenii Shatoknin已经为多家知名企业如思科、StripePMA、HUGO PFOHE等提供过AI解决方案。
Llama 3开源后,Arsenii Shatokhin迅速发现了这款开源大模型的的实用性问题,“Llama 3比之前发布的任何开源模型都大的多,即使是现在,我们也只有一两个客户拥有足够的资源来精调、甚至只是运行这款700亿参数的大模型。”

对于他的客户而言,使用这款开源大模型,反而不如闭源的商业大模型效率高。他分析说,闭源大模型的API优化效率更高,“因为这些API是专门为模型构建的,并且尽可能地进行了优化,你只需要为你使用的东西付费,而无需其他费用。”与之相对,如果在开源模型中开发这样的优化系统,“是非常复杂的”。
开闭源之争是大模型行业近期热点,但与Linux、安卓等系统开源不同,越来越多AI行业人士表达了对闭源大模型的认可,并纷纷指出开源大模型存在的各项问题。
“开源大模型会越来越落后”,不久前,百度创始人、董事长兼CEO李彦宏在演讲中指出,“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。”
当前,开源大模型与以往的开源系统存在明显差异。在开发者社区,多位网友指出,当前的开源大模型并不是真开源,仅仅是开放参数,而训练代码、训练数据、算法都未开源,依然是一个“黑盒子”,从而也会带来几项明显问题:
1) 问题难解决:开源模型仅提供API接口和下载,开发者连一行源代码都看不到,如果模型运行出现问题,难以找到原因,也很难及时调整、修正;
2) Post-pretrain消耗资源大:开源大模型就像一座建好的毛坯房,很难即开即用,要想使用还得经过Post-pretrain,需要消耗巨大的算力资源。正如美国AI创业者所说,大部分公司根本没有足够算力来精调和运行。相对来说,闭源的商业模型经过多次优化,已经可以“即开即用”。
3) 安全隐患:海外开源模型均未经过安全测试,在使用中为确保安全性问题,需要再经过多次精调,不仅有安全隐患,而且进一步加大了使用成本。
同时,也因为当前的开源大模型并不是“真开源”,仅仅是“开放”,因此无法像开源系统一样实现“众人拾柴火焰高”,在持续的迭代进步中,与闭源模型的差距会逐步增大。
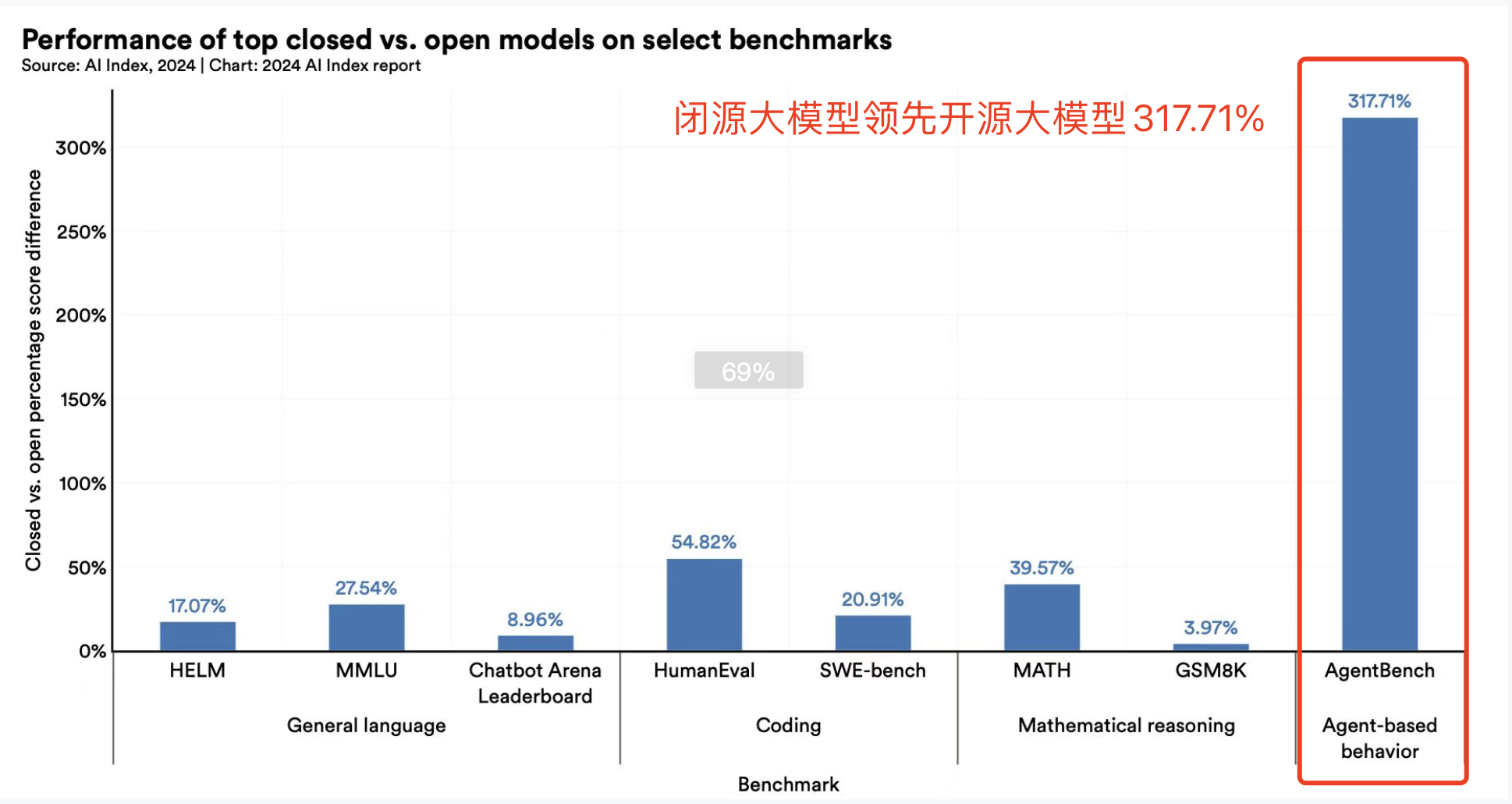
近期,美国斯坦福人工智能研究院院长李飞飞带领团队发布AI Index报告显示,在10项针对大模型的评测中,开源大模型全面领先闭源大模型,尤其是在最能体现模型应用和智能体能力的AgentBench项目上,闭源模型评分为4分,而开源仅为0.96,两者差距高达300%。