
实测strawberry中有2个字母“r”?不会比大小的大模型也几乎数不对数,数理能力差到惊人!
@科技新知原创
作者丨王思原编辑丨赛柯
谁能想到,号称“超级大脑”的大模型,竟然在几道简单的数学题上败给了小学生。
近日,国内火热的音乐节目《歌手》中,孙楠与外国歌手的微小分数差异,引发了网友关于13.8%和13.11%谁大谁小的争论。
艾伦研究机构成员林禹臣将此问题抛给了ChatGPT-4o,但结果令人吃惊,最强大模型竟然在回答中给到了13.11比13.8更大的错误答案。
随后Scale AI的提示工程师莱利·古德赛德基于此灵感变换了问法,拷问了可能是目前最强的大模型ChatGPT-4o、谷歌Gemini Advanced以及Claude 3.5 Sonnet——9.11和9.9哪个更大?然而几家头部大模型的错误回答,也让该话题传播开来。
而面对如此简单的问题,国产大模型表现如何呢?为此,我们也对国内7款主流AIGC产品文心一言、通义千问、腾讯元宝、字节豆包、讯飞星火、智谱、Kimi进行了比小学数学更简单的“单词字母数识别”测试,结果令我们大吃一惊。
Part.1
7家大模型,几乎全翻车
首先我们向7款大模型产品询问同一个问题,“strawberry中有几个字母r”?
大模型新星Kimi,斩钉截铁且不加解释的表示有1个字母r,不过当我们再次询问时,Kimi竟打翻了自己第一次的错误答案,给到了第二个错误答案。再三追问后仍是没能给到正确答案。
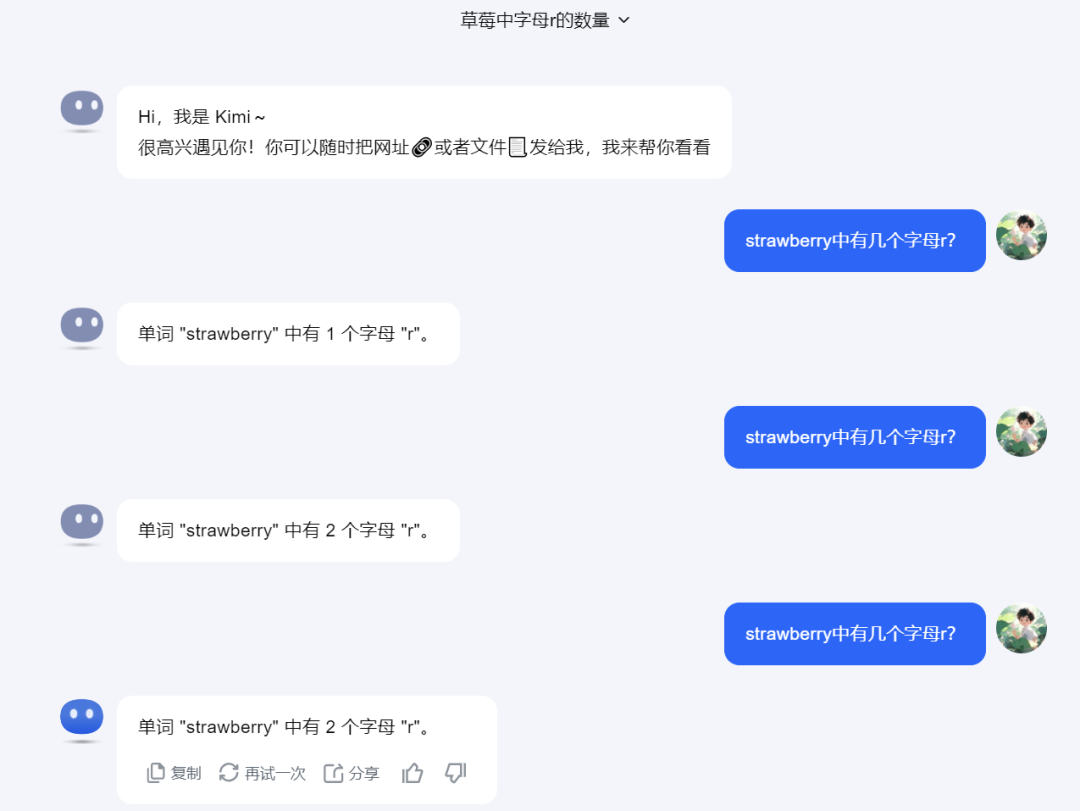

来源:科技新知(Kimi)
智谱AI旗下的智谱清言ChatCLM给到的也是错误答案。
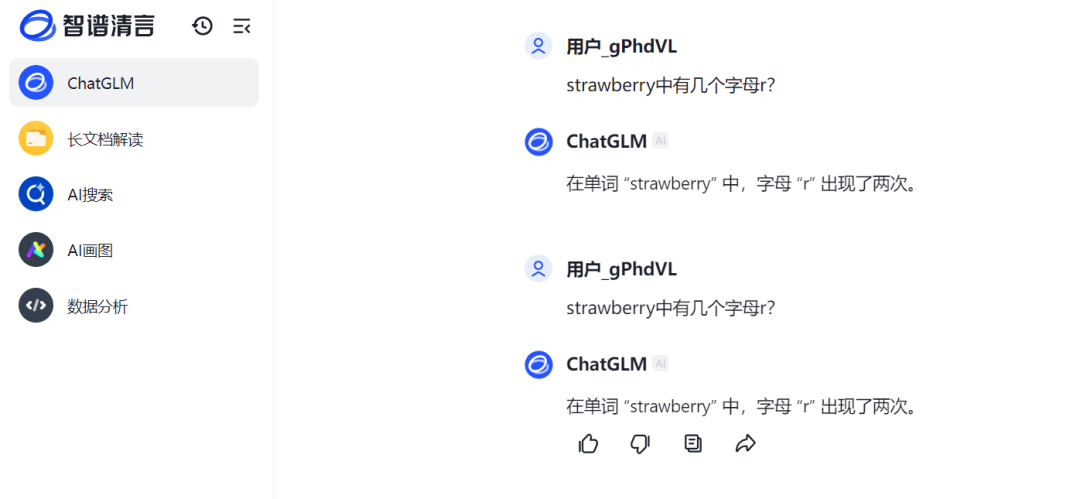
来源:科技新知(智谱清言)
科大讯飞的讯飞星火对话在回答这个问题的时候开启了联网搜索,给到一个错误答案后,还一本正经的告诉我们这2个r的位置。但可惜的是,星火对话给到的位置有一个也是错误的。
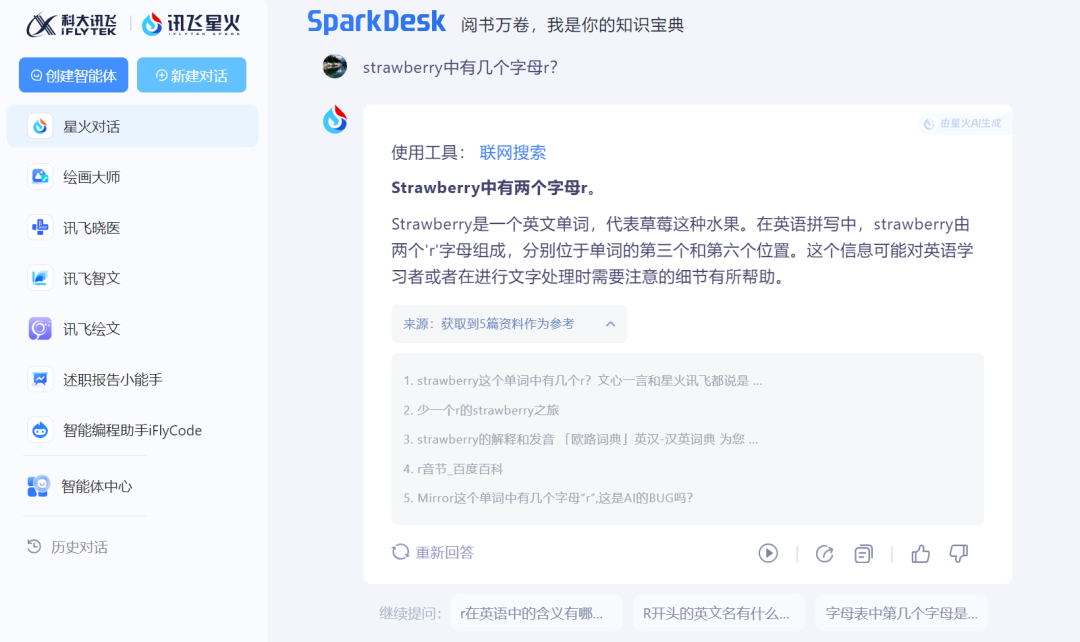
来源:科技新知(讯飞星火)
不过也有表现不错的,百度的文心大模型将strawberry每个字母都进行了拆分,然后进行统计,给到了正确结果。
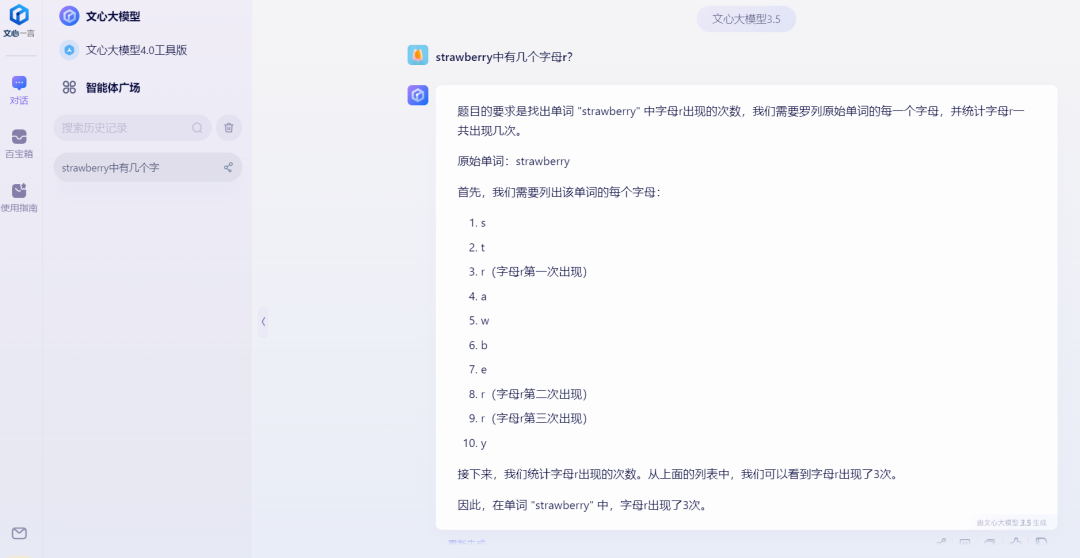
来源:科技新知(文心大模型)
阿里旗下的通义千问在第一次回答中给到了一个错误答案,并且阐述的位置也是错误的,第二次虽然再次给出了错误答案,但其回答中识别到了3个字母r,只是一句“注意虽然 “rr” 是连续的,但它们仍然被计算为两个单独的字母。”让人摸不到头脑。
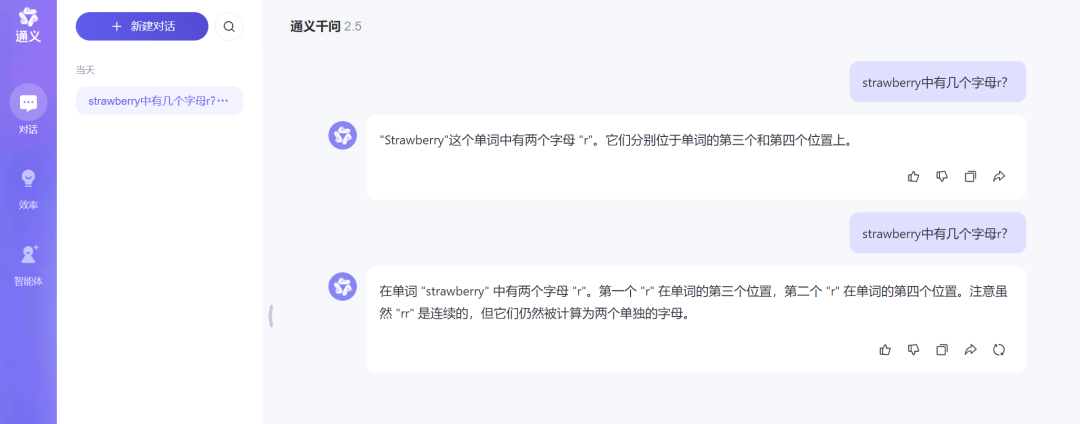
来源:科技新知(通义千问)
于是我们追问了“为什么rr被计算为两个单独的字母”,通义千问竟然又否认了刚才的回答,称“在 “strawberry” 中,两个 “r” 字母可以影响周围音节的发音,但它们仍然是两个独立的字母。”
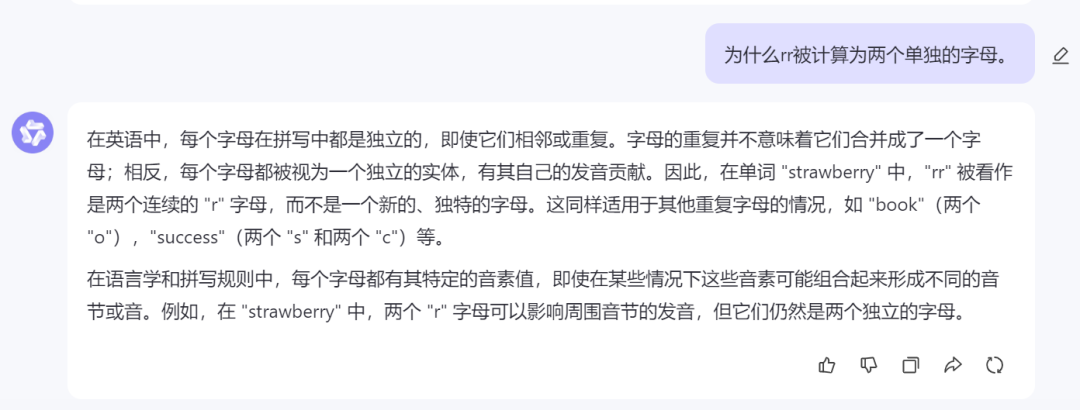
来源:科技新知(通义千问)
腾讯元宝在回答这个问题时采用的是假设法,假设了字母“r”的数量为未知数x,然后通过查看单词“strawberry”并计数字母“r”得到x的值,最后给到的答案是正确的。

来源:科技新知(腾讯元宝)
表现良好的还有字节豆包,直截了当的给出了正确答案,并且还举了两个例子来证明这个简单的问题难不倒它。但是,也是豆包的这两个例子出卖了它在识数能力上的问题。豆包称“car”这个单词只有1个“r”,“mirror”则有2个“r”,而“strawberry”比它们都多,有3个。
问题显而易见,“mirror”中有其实是有3个“r”,并非2个。于是我们又追问了一下“mirror中有几个字母r”,豆包给到的答案仍然是2个,并且又举了两个错误的例子,称“father”这个单词有2个“r”,而“orange”里面则一个“r”都没有。这多少让人认为豆包的正确回答有“蒙”的嫌疑。
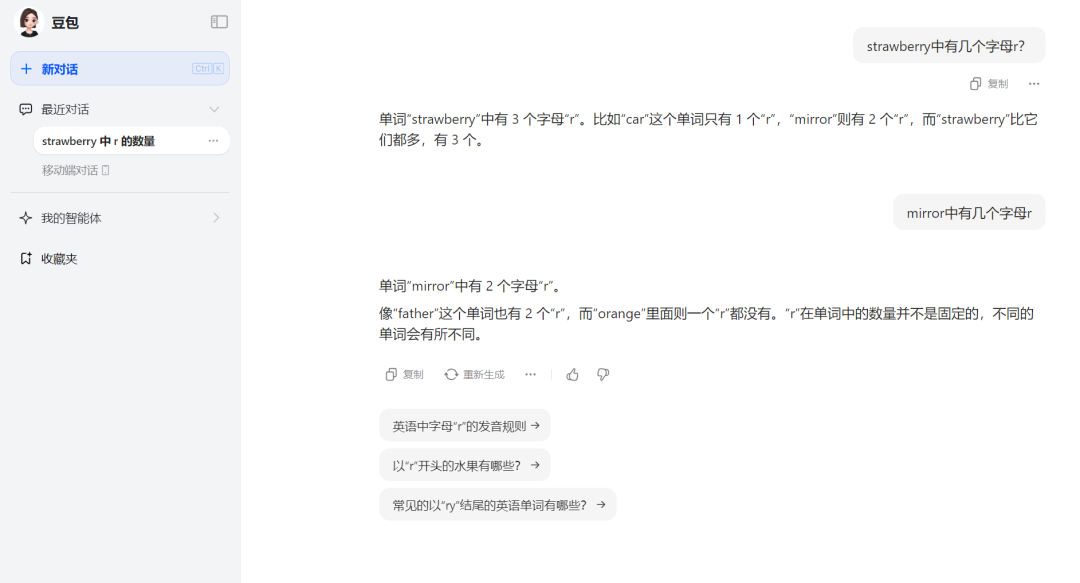
来源:科技新知(豆包)
通过这个简单的测试我们可以看到,7家大模型中有5家都有“不识数”的嫌疑,于是我们又将这个单词进行拆分成2个更简单的字母,测试这些大模型能否给到正确答案。
Part.2
拆分测试,揭露大模型逻辑短板
为了引导大模型,尽量使大模型给到正确答案,我们这部分将分为两个问题,一个是“str中含有几个字母r,berry中含有几个字母r,他们一共含有几个r?”,另一个是“那str和berry合在一起是strawberry,所以strawberry中含有几个字母r?”
不过,被寄予厚望的Kimi还是让我们失望了。将strawberry拆分成两个简单的单词后,Kimi仍没给到正确答案。

来源:科技新知(Kimi)
同样,智谱清言在这一轮也没能给到正确答案。并且其给出的解释也与Kimi一致,都认为berry中有1个字母r,所以才导致strawberry中少了1个r。

来源:科技新知(智谱清言)
有趣的是讯飞星火,当我们将单词分开提问时,星火对话能够给到正确的回答,并且识别到了berry中有2个字母r,不过看星火对话给的解释是将这两个字母当作字符串,用编程的方式来查找所得。但不管怎样,答案确实是正确的。
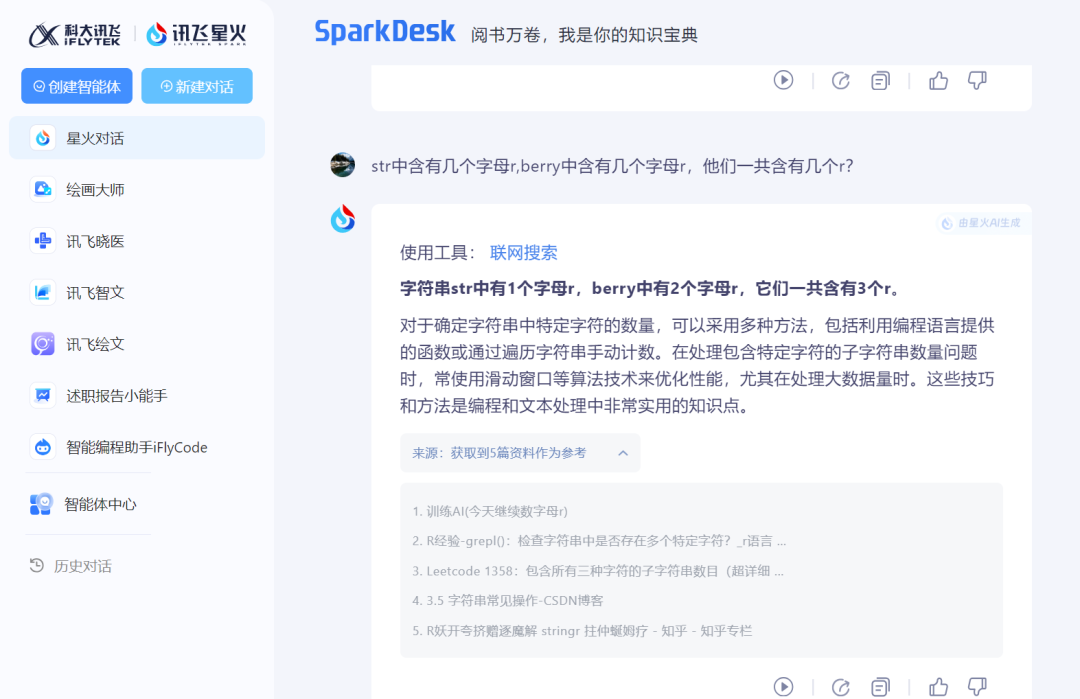
来源:科技新知(讯飞星火)
而当我们认为讯飞星火又行了的时候,再次询问“那str和berry合在一起是strawberry,所以strawberry中含有几个字母r?”,但讯飞星火仍然给到的是错误答案。
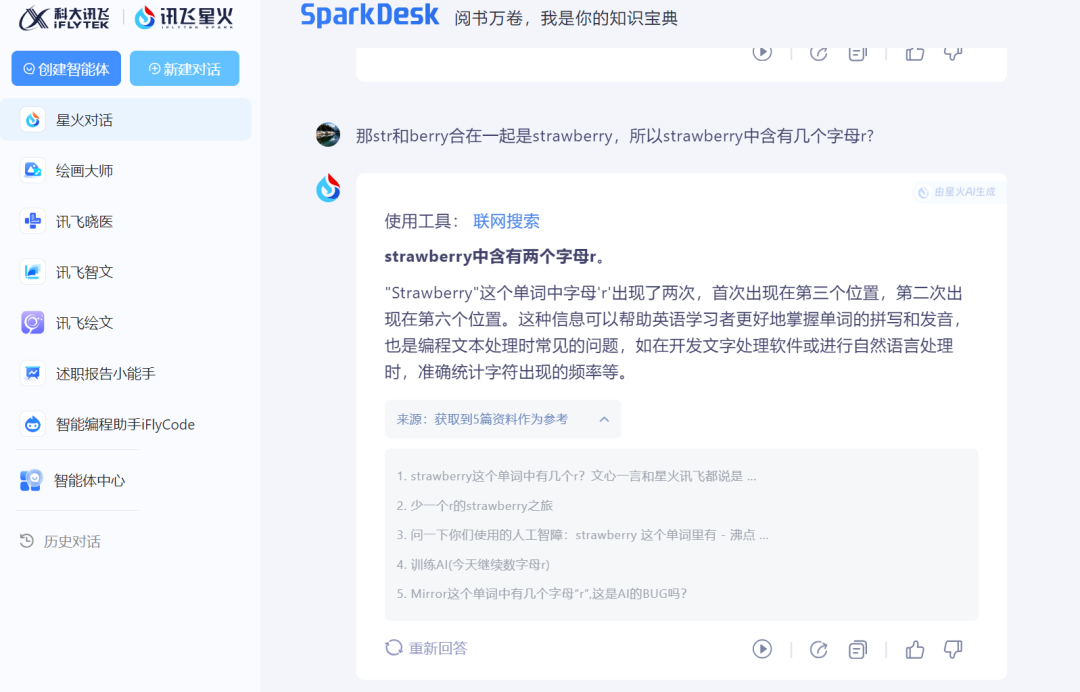
来源:科技新知(讯飞星火)
上一轮表现出色的文心大模型这次并没有给到正确答案,它与Kimi和智谱清言都认为“berry” 中有1个“r”,而追问两个单词合在一起有几个r后,文心也是给出了2个的错误答案。
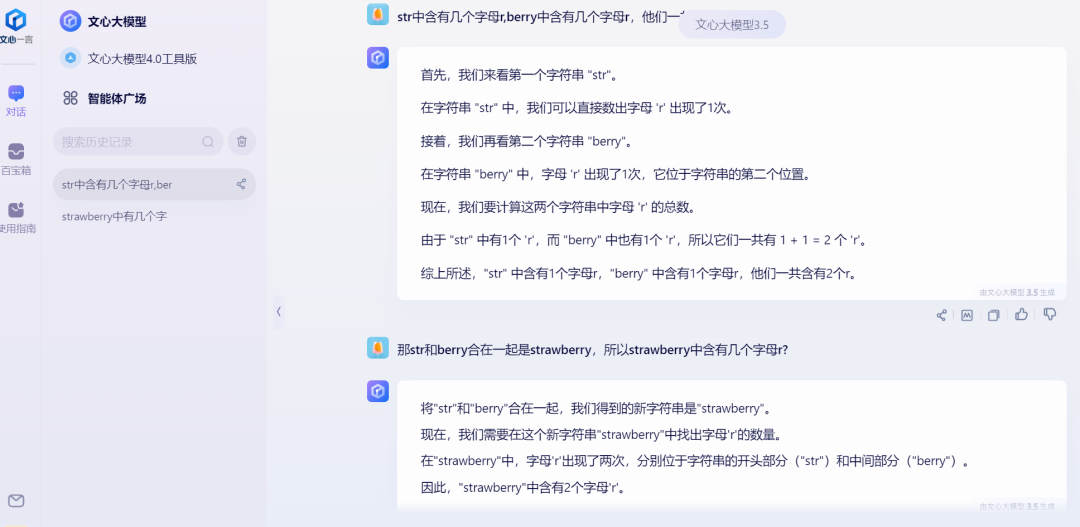
来源:科技新知(文心大模型)
通义千问这次的表现让人吃惊,不但准确的给出了答案,而且还给了代码级别的计算过程。
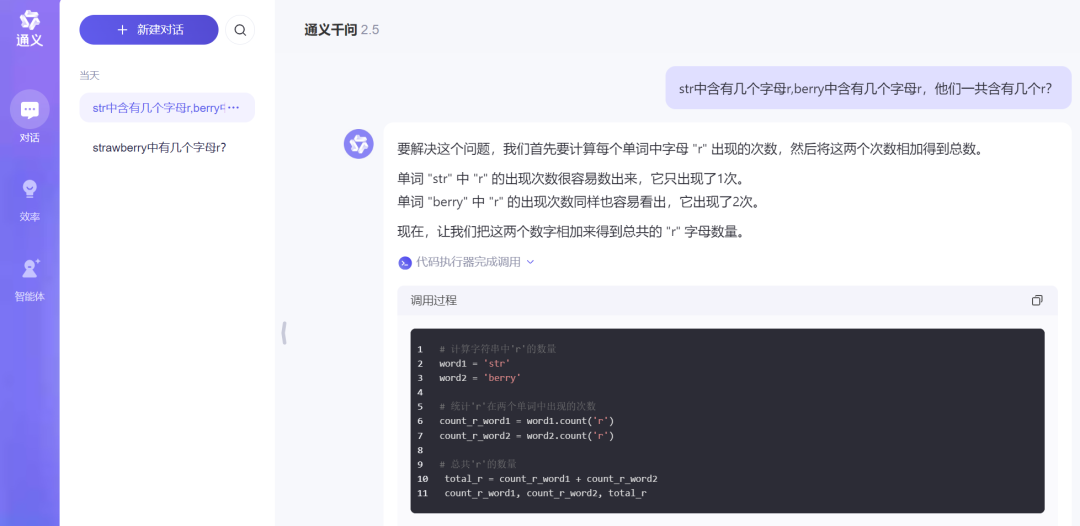
来源:科技新知(通义千问)
当我们再次问strawberry中含有几个字母r时,通义千问也非常有逻辑的地告诉我们可以直接在 “strawberry” 中查找 “r” 的出现次数,而不必依赖于之前的组合。
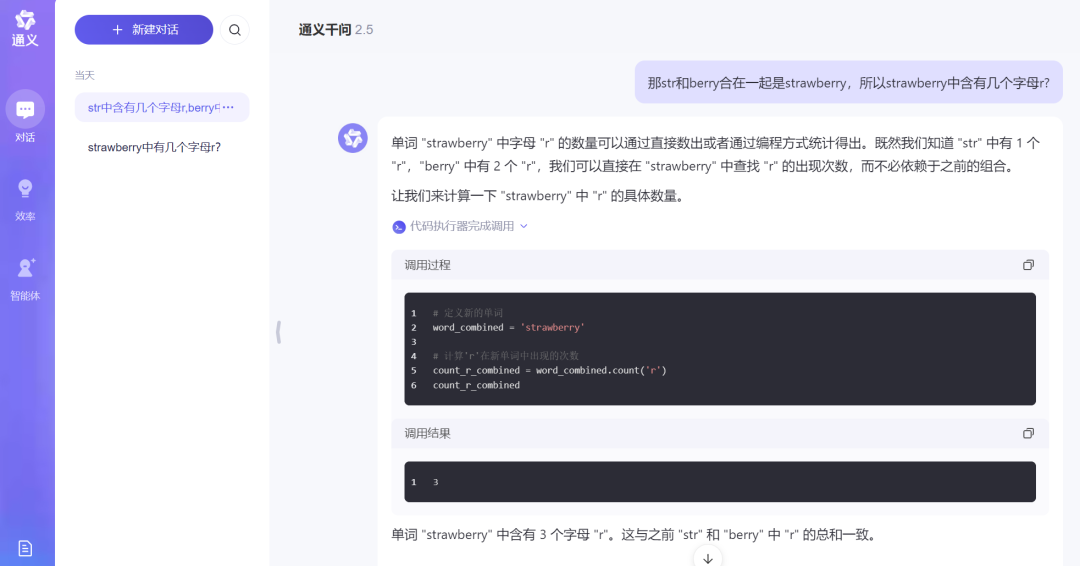
来源:科技新知(通义千问)
腾讯元宝的表现也足够稳定,简单迅速的给到了正确答案。
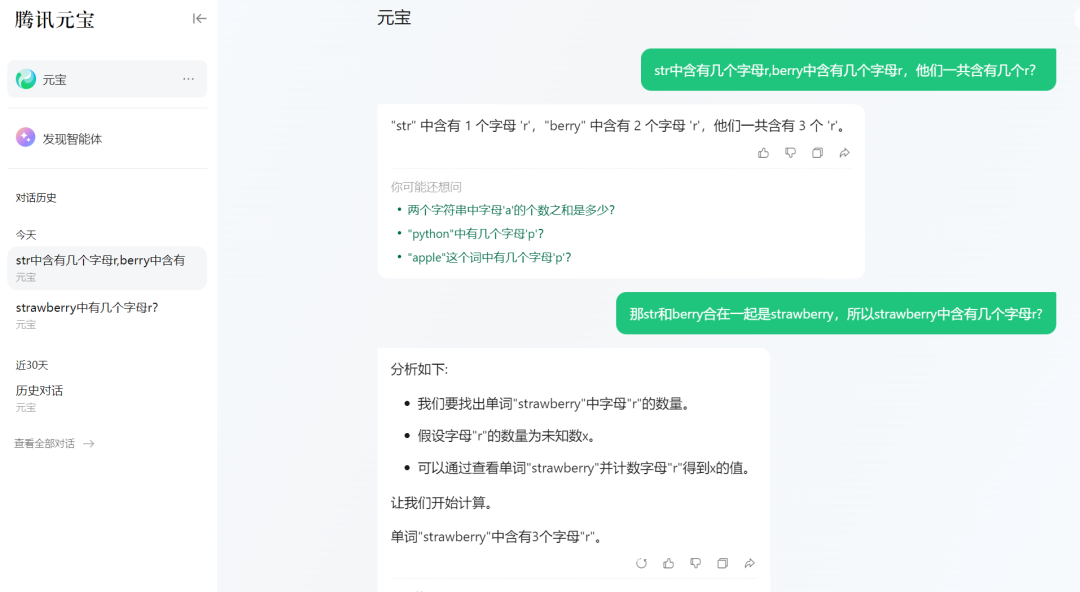
来源:科技新知(腾讯元宝)
豆包在这一轮也给到的正确答案,但喜欢举例的豆包,再次举了一个错误案例。所以其数数字的水平和逻辑到底怎样,仍是未知。
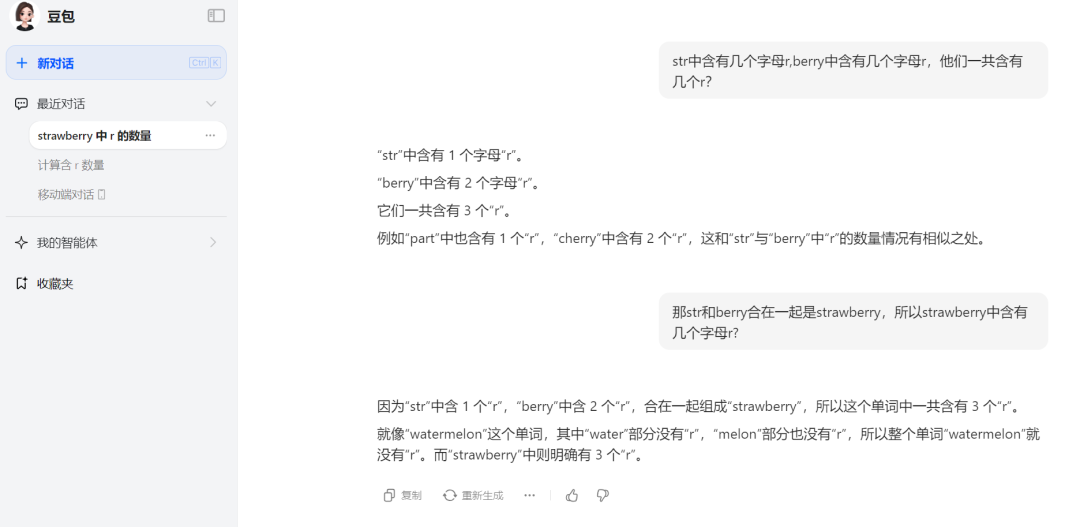
来源:科技新知(豆包)
两轮简单的小测试下来,7家国产大模型只有1家表现稳定,其他6家均出现了不同程度的错误,这到底是怎么回事呢?
Part.3
数学不好,本质是能力问题
这类大模型说胡话的现象,在业界被称为大模型出现幻觉。
此前,哈尔滨工业大学和华为的研究团队发表的综述论文认为,模型产生幻觉的三大来源:数据源、训练过程和推理。大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉。此外,大模型还可能会出现长尾知识回忆不足、难以应对复杂推理的情况。
一位算法工程师认为,生成式的语言模型更像文科生而不是理科生。实际上语言模型在这样的数据训练过程中学到的是相关性,使得AI在文字创作上达到人类平均水平,而数学推理更需要的是因果性,数学是高度抽象和逻辑驱动的,与语言模型处理的语言数据在本质上有所不同。这意味着大模型要学好数学,除了学习世界知识外,还应该有思维的训练,从而具备推理演绎能力。

不过中国社科院新闻与传播研究所所长胡正荣也指出,大模型虽然是语言模型,但这个语言不是人们通常理解的字面意思,音频、解题等都是大模型可以做的。从理论上看,数学大模型这个技术方向是可行的,但最终结果如何,取决于两个因素,一是算法是不是足够好,二是是否有足够量的数据做支撑。“如果大模型的算法不够聪明,不是真正的数学思维,也会影响到答题的正确率。”
其实对于大模型来说,对自然语言的理解是基础。很多数理化的专业知识并不是大模型的强项,并且很多大模型是利用搜索把之前已有的解题的经验和知识的推理相结合,可以理解为在搜索内容上进行理解,如果搜索内容本就是错误的,那么大模型给到的结果必然错误。
值得一提的是,大模型的复杂推理能力尤为重要,这关乎可靠性和准确性,是大模型在金融、工业等场景落地需要的关键能力。现在很多大模型的应用场景是客服、聊天等等,在聊天场景一本正经胡说八道影响不太大,但它很难在非常严肃的商业场合去落地。
随着技术的进步和算法的优化,我们期待大模型能够在更多领域发挥其潜力,为人类社会带来更多实际价值。但通过这次对国内主流大模型的简单测试,也警示我们,在依赖大模型进行决策时,必须保持谨慎,充分认识到其局限性,并在关键领域加强人工审核和干预,确保结果的准确性和可靠性。毕竟,技术的最终目的是服务于人,而不是取代人的思考和判断。