
智能汽车行业如此内卷智能驾驶,最后的终点在哪里?
从去年下半年开始,蔚来、小鹏、理想和比亚迪等车企们向智能驾驶领域快速地奔跑起来,纷纷提出以BEV+Transformer或OCC占用网络为关键技术的无图城市NOA方案。
再到今年,由于受到特斯拉的启发,整个智能驾驶行业又纷纷奔向端到端技术上,就目前来看几乎所有主流车企、L2+智驾方案供应商们都已经提出了各自的端到端技术架构,以至于让“是否应用端到端技术”成为目前考量智驾方案是否掉队的一大指标。
以技术趋势角度来看,行业内对于智能座舱的发展有着一定的共识——最终要实现真正的自然和主动交互,让整个智能汽车与驾乘用户的交互上更加人性、自然和聪明。
但对于智能驾驶的发展上,按照飞说智行的观察,截至目前还没有这样明确的共识。
飞说智行曾在《从BEV感知到端到端模型,智驾行业“追热词”为抢技术终局优势?》这篇文章中引用的《端到端自动驾驶行业研究报告》为例,智驾行业对于“端到端技术是否是智驾终局”的判断上,都呈现出三种不同的阵营。
正因如此,智能驾驶行业中有越来越多人问出了开头的那个问题。虽然从技术层面来看,这一问题目前没有确定的答案,但并不意味该问题就没有答案。
因为从本质上看,L2+的智能辅助驾驶,最后为其买单和使用的人群,都是广大的消费者。因此,在飞说智行看来,智能驾驶就是一个强体验的产品。以此为角度,智能驾驶的发展趋势自然就浮现出来了——让消费者真正爱用智能驾驶功能。
值得注意的是,要做到“爱用”这一目标,并不是一蹴而就的,而是需要先迈过“能用”和“好用”两个阶段。目前主流的智能车企们都已迈过能用的1.0时代,正无限接近好用的2.0时代。那么,爱用的3.0时代,何时能实现?
就在最近的成都车展上,飞说智行受理想汽车邀请,在媒体圆桌交流会上听到了这个问题的答案。
按照理想汽车智能驾驶研发副总裁郎咸朋的表态,他们预计最早今年底、最晚明年上半年就会让用户们爱用理想的智驾产品。要实现这一目标,则是需要基于会在同期落地的“有监督的自动驾驶”功能。
不可否认,在目前整个智能驾驶行业中,理想汽车是为数不多在公开场合下提出要落地交付自动驾驶功能时间表的车企。
理想汽车会这样敢于人先,主要得益于他们在智能驾驶领域获得的诸多正向反馈。
根据飞说智行获悉,理想汽车在今年7月底开始,向1000名内测用户推送了基于端到端模型、VLM视觉语言模型和世界模型的全新自动驾驶技术架构,开始了“千人团内测”。
经过不到一个月的内测,千人团用户总城市NOA行驶里程达到21.1万公里,单日城市NOA驾驶最长里程391公里,最为关键的MPI(平均接管里程)上,从第一个版本的12.2公里,提升至目前的21.8公里,换句话说,用户开启智驾功能后,车辆自主驾驶的距离越来越长。
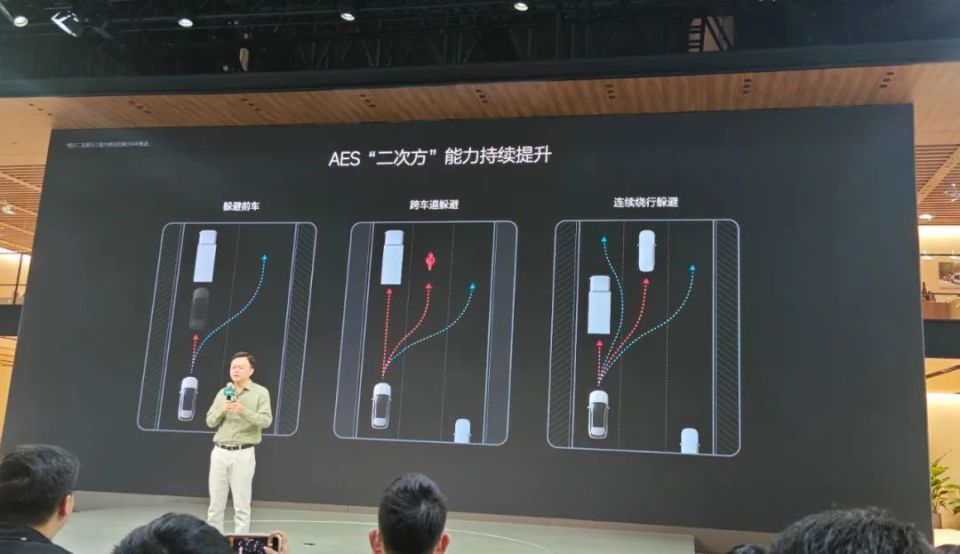
除了城市无图NOA之外,理想在智驾主动安全方面也有功能的迭代。今年7月中旬,理想汽车正式推送全自动紧急转向AES。这一功能简单说,就是当车辆AEB(自动紧急制动系统)全力制动也无法避免碰撞的物理极限场景下,AES功能可以无需人工接管自主执行车辆的避让,避免碰撞事故的发生。
但这一功能此前也存在一个Bug,就是当车辆执行一次AES避让后,如果临近车道也有车辆的话,那么碰撞也无法避免。或许理想也意识到了这一风险,因此在此次成都车展上也宣布他们正在研发连续两次避让的AES能力。

图源飞说智行摄
未来,AES能力也会涵盖更高的极限性能和更多的场景能力,例如跨越车道避让、连续绕行避让等能力,以及应对极限近距离加塞、极限行人鬼探头等危险场景。
要实现有监督的自动驾驶,自然少不了算法层面的迭代,而这背后也需要基于算力和数据的支持。在这两方面,理想汽车也在积极为此做着准备。
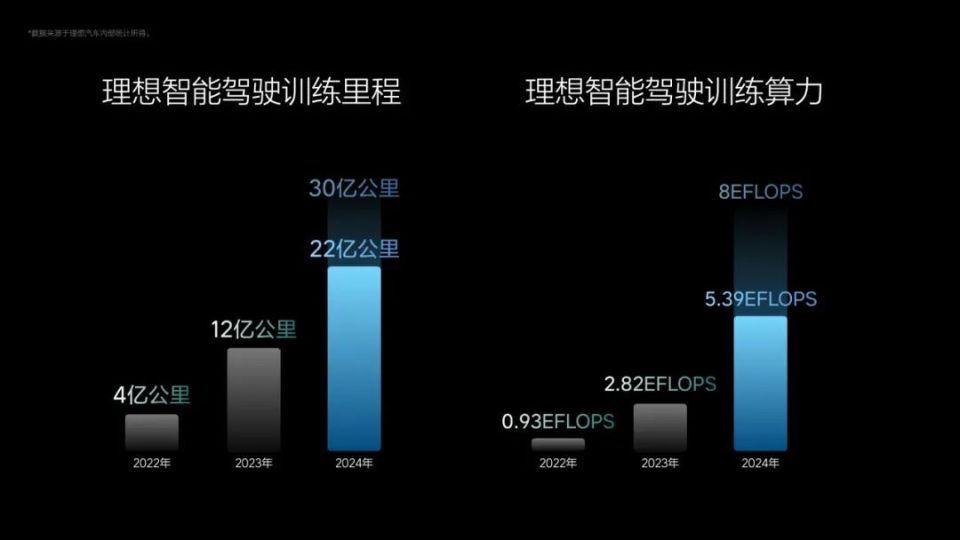
首先在算力上,按照郎咸朋的介绍,理想汽车当前训练算力达到5.39 EFLOPS,预计到今年底将超过8 EFLOPS,理想汽车每年在训练算力的投入超过10亿元。
再则是数据上,基于理想汽车快速增长的销量规模,目前积累的训练里程已超过22亿公里,预计到今年底将超过30亿公里。
图源理想汽车
数据多并不代表就能训出好的算法和模型,而是需要高质量的数据“养料”。
对此,理想汽车采取了“两条腿”走路的方案。一方面,对于车辆跑出来的的数据,用“问诊台”和“错题集”等创新性的AI模型来做分类和针对性的训练;另一方面,通过生成式数据,来实现闭环的仿真训练,来提升模型对于世界的认识和理解能力
基于以上分析,在飞说智行看来,此前在智能化领域“慢几步”的理想汽车,能用很快的时间完成追赶、并在目前站在智驾行业第一梯队中,属实正常。但对于理想来说,随着特斯拉FSD入华、以及整个智驾行业更加内卷,未来也会有一定的挑战。
以下为飞说智行与理想汽车智能驾驶研发副总裁郎咸朋和理想汽车智能驾驶高级算法专家詹锟的深度对话,略有删减和修改:

1、在端到端技术上的思考和探索
飞说智行:现阶段理想智驾研发架构中分为算法研发和量产研发,分别对应着不同的小组,小组对应的是端到端不同模块。随着未来算法的迭代和成本的优化,未来的组织架构是否会进行调整?朝哪些方向来做调整?这个过程中有遇到哪些难题?
郎咸朋:在整体战略规划和业务战略里,我们对于业务组织有清晰的布局。组织根据业务变化,业务的目标和迭代来进行战略调整,这就是我们的BLM流程(业务领导力模型),我们原来叫LSA流程(理想汽车战略分析法)。
我们的组织变化要追溯到去年或者更早。我们把智能驾驶作为公司战略之后,业务和组织才开始发生迭代和变化。在去年秋季的雁栖湖战略会,我们首次明确提出PD和RD都非常重要,但是其实在那之前PD、RD已经有了,只是在战略会上,进一步明确了将智能驾驶和RD都作为公司级战略展开,所以业务发生了变化。接下来组织会不会发生变化,要看跟业务是否有关联。
飞说智行:目前所有的车企能够量产车型都是L2级辅助驾驶,理想汽车端到端+VLM怎么保证智驾的安全?
郎咸朋:从流程上来讲,内部主要研发流程分为产品交付研发流程以及智能AI的研发流程,两个流程相互配合。
端到端+VLM这套技术系统在一个月的测试过程中,虽然开启城市NOA功能始终是通过拨两次方向盘杆,实现从A点到B点的智能驾驶,但是模型迭代的能力却在不断提升。
在模型迭代的时候,整个功能跟原来完全一样,所以这个功能之前做的测试仍然有效。对于这个能力的表现,我们用生成和重建的方式做模型的泛化测试和检验,比实车在全中国驾驶测试好得多。这是我们在 AI 时代到来之后,对于产品研发的深度思考,从而带来的研发变化。
安全的另外一层含义就是:怎么能在产品交付之前,做更多更有效的测试。如果用实车做测试,一方面是成本,另一方面是是测试效果可能达不到交付有监督自动驾驶的程度,特别是当模型迭代比较迅速的时候。
我们现在用Diffusion transformer技术,再加上3DGS技术,能够把曾经遇到过错题以及遇到过的场景,举一反三地形成模拟题,实现不断地测试模型能力,不断地优化各个城市表现。
我们在每一个维度上都有非常严格的打分,比如安全、法律法规等维度。如果不安全、不合规,模型就不能交付给用户。现在在千人团内测阶段,还没有到量产阶段,所以在安全、合规方面的要求会更加严格,确保我们的产品是一个安全可靠的产品。
詹锟:我从技术角度来说,我们有安全兜底模块,甚至有些东西我们会保证它有绝对的下限。以前写了很多规则应对不同的场景,但是现在只需要写下限的规则,上限全靠端的端 、VLM去捕捉,甚至有些防御性驾驶,VLM都可以提前告诉系统,比如丁字路口、坑洼小路等,这些都在一定程度上提升了系统安全性。
无论是数据还是算法,都是在把安全性往上提升。并不是大家说的那样,用端到端了安全就差了,这是针对设计不完善的一种想法。另外,/AES其实是在最极端的情况下,最兜底的一种保证绝对安全的方式。这就是用算法、冗余一起来解决安全问题。
飞说智行:现在从生成到输出,对于传感器包括数据需要有一些质量监测,这个过程中如果出现恶意攻击,甚至说出现各种故障,这种情况理想汽车怎么解决这数据安全的问题?
詹锟:面对数据被污染或者传感器遭受恶意攻击,以及对神经网络进行对抗性破坏,我们已经将这种情况涵盖到整个网络训练过程中。
模型训练并不是针对单一的传感器,比如一个传感器损坏,我们能够通过BEV解决。即使在雨天某个传感器脏污的很厉害,我们依然能稳健驾驶,同时能给用户对应提醒,会告诉你找个安全的地方停车,不会让系统直接失效。
因为有Radar、Lidar等多个传感器,各个传感器在不同环境下能冗余互补,单一的攻击很难起效,这就是为什么很难有单一的攻击策略能让智驾系统失效,因为在技术上做了很多防护。
飞说智行:智能驾驶的技术升级是否能带来销量提升?
郎咸朋:销售有几个非常重要的漏斗。第一个是品牌,只有用户认可品牌后才会比较智驾、电池、续航等。如果说一开始品牌就不在老百姓的选择范围内,那可能做什么都跟销量没有关系。
飞说智行:目前,理想AD Max由两颗Orin X来支撑现在测试的能力开发,端到端方案对车端算力的要求是什么样的?是更高还是更低?那么未来随着端到端上车会不会变得更加强大?这究竟是个什么样的关系?能不能解读一下?
詹锟:各家在使用算法的时候,都会跟自己的硬件做匹配,无论是用地平线方案,还是Orin方案。双Orin X可以完美适配我们的双系统方案,如果要给出一个固定的上限,不是很好直接预测或配置。但是我们可以知道,随着算力增加,整个能力是一个非常线性的增加,包括特斯拉也证明了12.5版本比12.3提升了五倍,这也完美符合这种大模型的Scaling Law。
对我们来说,到Thor阶段我们肯定会有一个更大规模数据量训练的端到端大模型,效果会进一步提升。我们可以看到它的趋势,我们会基于芯片对它进行相关算法的定制化调整;同时模型规模越来越大,最后产出的端到端效果会越来越好。
另外,其实也可以看到特斯拉现在正在宣传2026年要做一个AI的芯片,大概有3000到4000 TOPS的水平,这个阶段是他在做Robotaxi的一个想法。我们也在持续关注高算力的车端芯片的性能。
郎咸朋:我补充一点,Thor芯片上车后,因为它的算力比现在Orin X又大了很多,那么我们会在Thor上更多地发展我们系统化VLM的模型能力。端到端模型我们认为是比较吃算力的,但是它使用算力的上限比VLM少很多,而且它有一定的上限,要1,000万clips,训练这样一个模型所需要的参数量非常大。
所以在向L4发展过程中,整个系统需要让它具备更好地应对未知场景的能力,而未知场景能力的提升,需要提升的是系统2,就是VLM的模型能力,所以我们现在22亿的产出量,将来可能再去扩大。
飞说智行:目前在理想的算法模型训练中,使用仿真训练和车辆跑出来数据的比例分别是多少?
詹锟:我们的评分体系是非常严格,不是所有的车主数据都会拿过来训练,我们会有非常严格的分数,分数会卡在3%-5%的水平,随着后面数据采集的越多,对质量的要求并不会降低,这是我们训练的体系。
22亿的数据里面只有高质量的数据有价值的数据会拿出来用。仿真我们会把无论是自动驾驶还是人开的不好的场景我们会拿进来用,这个比例随着用户使用程度越来越高,我们会越来越收紧。
相当于大的仿真考试题库一样,我们会持续验证是不是每个版本都可以了,是一个积累的过程,并不是说我单独选择一个值。目前我们有一千万公里的仿真测试集,这是实车测试不可能在短期内实现的。
郎咸朋:我们每个模型的发版至少进行了一千万公里的测试,不仅节省做路试的时间,效果也有显著的提升。而且错题集一定是有代表性的场景,比如有安全类问题、效率类问题等。今天我们在发布会上重点讲了系统1和系统2模型,后面我们会给大家介绍更多训练模型相关的信息。
现在我们做到了每两到三天迭代一次模型,这其中最关键的技术就是AI评价体系,也就是测试系统。测试系统需要很多人、很多车进行路试,消耗大量的人力和物力。但是我们觉得这依然不够,第一模型迭代速度过慢,第二场景收到限制,我们不可能将同样的场景开过两次,也不可能在夏天去模拟冬天的场景,所以我们做了AI评价体系,上千万公里的错题集对应的是上百万个case。
在错题集之外我们还有模拟题,将以前的错题在不同的场景下生成用来评测是否依然能够开的比较好,而且要达到我们80分的及格线。此外我们在云端有非常强大的模型,收集到有问题的用户数据之后,模型能够帮助我们进行分类并且直接放入错题库,这样的效率是非常高的。如果我们想要去训练模型、迭代模型,这样非常厉害的评价系统是必须的,就像考试要有人批卷子,有人告诉你哪里对哪里错。
现在路试的数据还没有用完,是22亿公里。我们到了100亿公里量级时候,可能路试的数据就不那么多了,那个时候我们在下一阶段会用很多的仿真数据。而且大家也可以看到生成模拟器的生成场景不仔细看的话是无法辨别是真实的还是模拟的。
我们做出“有监督的自动驾驶”以后,这套模型迭代会比现在快很多,能够直接生成训练数据,这样我们在训练下一阶段的L4自动驾驶的时候,我们肯定会用到仿真数据。
2、智能驾驶行业的未来在哪里?
飞说智行:现在行业中有个共识,智能驾驶会分为能用,好用和爱用三个阶段,目前理想汽车的智驾做到了哪个阶段,大概需要多长时间可以做到“爱用”阶段,哪一年可以达到这个目标?
郎咸朋:能用、好用和爱用这其实是由用户决定的。我们的千人团车主以及购买AD Max的车主比例显著提升,我认为这就已经进入到了“能用”阶段。我认为端到端内测推送之后就是一个“好用”的状态。我自己上下班的智能驾驶比例达到95%以上,好用和爱用是培养大众对于智能驾驶理念认同的过程。
我们现在的千人团、万人团包括一些发烧友车主,他们依然处于早期大众的阶段。当步入晚期大众,也就是50%的消费者在没有智能驾驶的时候会不习惯甚至不会开了,等进入到这个阶段就是真正的“爱用”阶段,或者说是必须要用。
理想汽车的研发迭代速度是非常快,我们最早今年年底,最晚明年上半年就会将这套“有监督的自动驾驶”量产交付,那个时候一定会让大家非常爱用这个产品。
飞说智行:全行业都在探索自动驾驶,没有一个共识方案,所以理想端到端+VLM进入市场的同时,还会不会有其他探索?关于智能驾驶的短期目标,或者最终目标是怎么样?
詹锟:第一个事实是,大家都在研发阶段、尝试阶段,我们之所以敢把目前的版本推送给用户,是因为我们觉得可以类比CNN深度学习网络时期,当时因为一个竞赛,CNN的性能优化了10%左右,性能和体验得到了大幅提升。
第二个事实是,在这个过程当中,不同数据、不同的模型结构、不同的训练方法,对模型的迭代都有帮助。这其实是各家都在做的一个关键,解决数据和训练算力的基础问题之后,我相信我们,包括特斯拉都能成功“炼丹”。但是炼丹第一步就是得有原材料,当原材料得到解决,炼丹的比例调整好,这个丹的作用才大。
类似于以前炼火药,按照一硝二磺三木炭的比例来,火药的威力就大,如果1:1:1做出来的就是“呲花”,这就是各家在迭代过程当中的一些技术诀窍。
我们和用户共同成长,所以我们也需要知道每一套模型实际的表现如何,我们内部有自己的测试,如果表现不好就会内部消化,这种模型就不让去用户使用,但是每当模型有迭代、有提升的时候,我们都会拿给用户去进行测试、验证,这是我们研发过程当中的一些迭代。
关于下一代方案,不知道大家有没有看上周智元的发布会,智元展示了G1到G5的具身智能过程。其实我们内部也有自动驾驶整个研发过程的阶段,我认为在现阶段,无论是对于理想汽车来说,还是对于特斯拉来说,其实都是在向双系统方向发展。
所以端到端肯定是一个非常好的阶段,我们认为已经达到了L3。我们想进一步向L4发展,其实就是需要端到端+VLM双系统,我们认为这是面向L4的一个终局方案。
那再往后,L4不是终局的话,我们还有L5,像智元发布的G5一样,我们肯定还会有一体化的、超大规模的统一模型,像GPT-4o模型。未来,肯定要把两个模型合在一起,实现手脑完全结合的大模型方案,这是我们之后要尝试,要探索的东西。
飞说智行:智驾行业的未来商业前景是怎么样的?
郎咸朋:我认为对于智能车,智能驾驶和自动驾驶是不可分割的一部分。如果收费,就会涉及到不缴费的智能车体验会不好。我们的智能驾驶功能是免费的,当技术和能力到了一定程度之后会催生出一些新的商业场景和模式。
大家现在会有很多的畅想,如果实现自动驾驶会有各种各样的场景、产品,现在端到端+VLM是一个分水岭,之前无论是有图还是无图,都是用非人工智能的方式来做智驾,我们做详细产品的需求、规划、拆解以及验证,而对于端到端,与其说我来测试它不如说我来体验它,体验一下它今天学到了什么样的能力。
所以大家要用不同的思路和眼光来审视接下来人工智能时代的自动驾驶,它一定会超越所有人的预期,我们提到一个月内迭代12代,会有些人觉得我们测试不充分,但是两个月,三个月,甚至一年之后就不会再这样想了,因为自动驾驶会大规模落地。
飞说智行:理想是怎么看待车企做Robotaxi呢?
郎咸朋:我认为Robotaxi是一个产品或商业的形式,并不是技术。在技术发展到一定程度之后,它可能会催生很多的商业形态,比如Robotaxi,Robobus等。第二,消费者的需求是不是已经到了大家更愿意用Robotaxi的阶段,或者用自己车来做Robotaxi。
当然还有一些相关的国家法规,国家法规激励新能源车,才能让我们走到现在,所以者和国家法规对这些产品形态的支持。